
Deploying Python ML Model on Hadoop with AWS Integration: A Step-by-Step Guide
As a Data Scientist, are you working on creating a Machine Learning (ML) model using Python? Then, consider deploying the ML model in a cloud-based environment like Amazon Web Services. AWS provides an easily scalable infrastructure with various cloud-based hosting solutions to support your ML models.
Once you deploy your ML model in AWS, you can focus only on improving your ML model’s performance functionalities instead of taking care of the underlying infrastructure!
So, let’s get to the main point: How do you deploy your Python-based ML model on AWS? What is the most suitable deployment process? Which AWS services or resources will you need?
In this step-by-step guide, you will find all the required resources to get started! So, let’s begin!
A Quick Review Of The Project Prerequisites:
Before you deploy the Machine Learning model, ensure that you have the following setup ready to begin:
1. A Hadoop cluster set up with relevant components like HDFS and YARN.
2. Install the Python Framework on your machine with the necessary libraries.
3. An AWS account with access to services like Amazon S3 and Amazon EMR.
4. An active account on GitHub, Postman, and Docker.
Now, let’s check out the entire deployment process through the below roadmap image:

Step 1: Setup Your AWS Account For Easy Integration
Let’s create a solid foundation by setting up your AWS account so that it can have the necessary credentials and tools to interact with other AWS services effectively.
1. Create an IAM User Account:
IAM (Identity and Access Management) is a fundamental AWS service that allows you to securely manage users and their access to AWS resources. Once you create a dedicated IAM user account, you can grant the account the necessary permissions to carry out specific tasks related to the ML model deployment.
2. Obtain SECRET KEY ID and SECRET ACCESS KEY:
AWS uses access key pairs (Access Key ID and Secret Access Key) to authenticate requests made through the AWS CLI or SDKs. So, select the newly created IAM user account from the dashboard to obtain the access key pairs:
➢ Navigate to the "Security credentials" tab
➢ Click on "Create access key"
➢ Note the displayed Access Key ID
➢ Download the CSV file with the Secret Access Key
These keys act as a secure way to establish the identity of the IAM user and enable programmatic access to AWS services.
3. Configure AWS CLI:
The AWS CLI (Command Line Interface) simplifies interactions with AWS services directly from the command line.
Configuring the AWS CLI on your local machine. Run AWS configure and provide your access key, secret key, and preferred region to initiate the deployment process. This establishes seamless communication with other AWS services without needing a web-based console.
Step 2: Prepare The Machine Learning Model With Python
Let's start by preparing the Machine Learning model. For the sake of this guide, we'll use a simple example of a newly created ML model.
1. Clone Your GitHub Repository
Create a new GitHub repository with the name of MLModelOnAWS. Clone the repository to your local machine using the provided URL.
$ git clone https://github.com/
$ cd MLModelOnAWS
2. Create Python Machine Learning Model:
Utilize a Jupyter Notebook or any preferred Python environment to develop and train your ML model. You can use the code below to create a simple ML model.
Here, we first imported the “pandas” library for data manipulation and the “joblib” library for efficiently saving and loading large NumPy arrays.
Next, we used the function “train_test_split” to split the dataset into training and testing sets. Next, we used the “RandomForestClassifier” as a machine-learning model for classification.
Next, we used the Placeholder comment to include code to load and preprocess your dataset. This step is crucial for preparing your data for model training.
Finally, you can create an instance of the RandomForestClassifier to train the Model. Fit the model to the training data (X_train and y_train) and help it learn patterns and relationships.
Use the “joblib.dump” to save the trained model to a designated folder (models) within your project directory. Now, your Phyton-based ML model is ready for use!
3. Packaging the Model for Hadoop
With your Python-based ML model developed, you must prepare it for seamless integration with your Hadoop cluster. To deploy the model on Hadoop, you must package it along with its dependencies.
Install Hadoop dependencies with additional libraries on your Hadoop environment to avoid compatibility issues during deployment.
Create a dedicated deployment director named "hadoop_deploy" to contain all the necessary components.
$ mkdir hadoop_deploy
Copy your trained ML model and any essential files or libraries into the deployment directory:
$ cp models/model.pkl hadoop_deploy/
Create deployment scripts that guide Hadoop in executing your ML model. These scripts may include instructions on loading the model, processing data, and generating predictions.
Use Hadoop's file transfer mechanisms of HDFS commands to move your deployment directory to the Hadoop cluster:
$ hdfs dfs -copyFromLocal hadoop_deploy /user/
Confirm that your ML model and deployment scripts are successfully transferred to the Hadoop cluster:
$ cp models/model.pkl hadoop_deploy/
This command should display the contents of your deployment directory. Now your model seamlessly aligns with Hadoop, it’s time to complete the AWS integration!
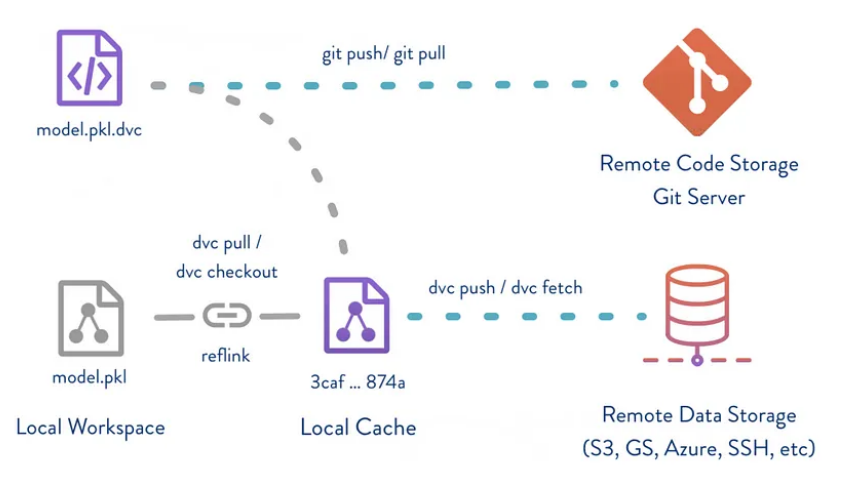
Step 3: Prepare Model with Data Version Control (DVC)
Now that your ML model is set with Hadoop Cluster, it’s time to ensure data version control with effective management. Data Version Control (DVC) offers a streamlined solution to track and handle large data files processed through the ML model.
Next, we will set up DVC to version control your ML model and save it remotely on an Amazon Simple Storage Service (S3) bucket to overcome GitHub size limitations.
1. Install & Initialize DVC:
Install DVC on your local machine. Open your terminal and run the following command:
$ pip install dvc
Navigate to your project directory and initialize DVC. This step establishes DVC in your project and prepares it for version control:
$ dvc init
2. Add Model to DVC & Commit The Changes:
Add your ML model file in the DVC for version tracking. This ensures that changes to your model are logged and can be reproduced easily.
$ dvc add models/model.pkl
This command creates a DVC file (models.dvc) referencing your model file. Now, commit the changes made by adding the model to DVC. This step records the current state of your model in the DVC repository:
$ git add models.dvc
$ git commit -m "Add ML model to DVC"

3. Set Up Remote Storage on Amazon S3:
To overcome GitHub's file size limitations and ensure secure storage, configure DVC to use an S3 bucket as remote storage. Replace
$ dvc remote add -d remote-storage s3://
This command configures DVC to use an S3 bucket named
Finally, push your ML model using the “$ dvc push” command to the remote S3 bucket. This step transfers your ML model to your AWS environment, where you can use it to integrate with other AWS services. Thus, your ML model remains reproducible and accessible across different environments.
Step 4: Create AWS ClousFormation Template To Deploy AWS Resources
This step builds on the ML model deployment achieved with DVC by introducing IaC for AWS resources and containerization for the ML application. So, it helps streamline deployment and ensure consistency across various AWS environments.
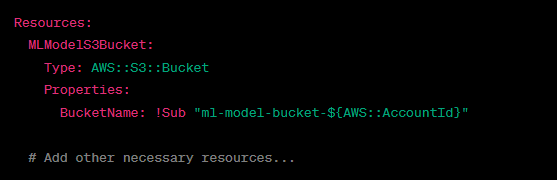
You can use a pre-build CloudFormation Template like the one below to create the S3 bucket, IAM roles, and other resources required to support your ML model functionalities.
Likewise, you can define other AWS resources you want to deploy using this template. Next, you can use GitHub Actions to automate the deployment of your CloudFormation stack.
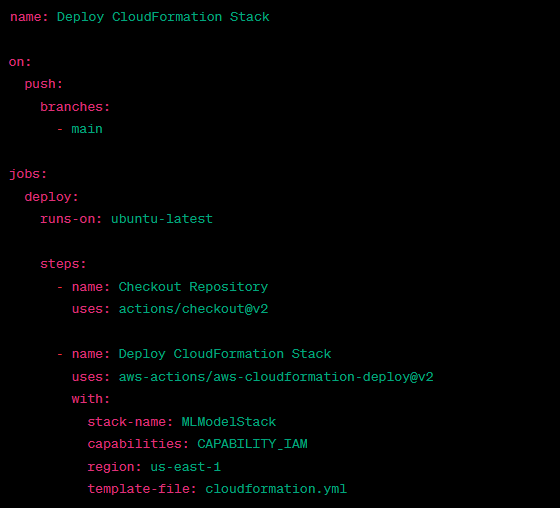
Here is an example GitHub Actions workflow that specifies the steps for deploying your CloudFormation template:
Upon successful execution, the CloudFormation stack creates the specified AWS resources like the S3 bucket. CloudFormation ensures that your AWS resources are reproducible and easily managed through code.
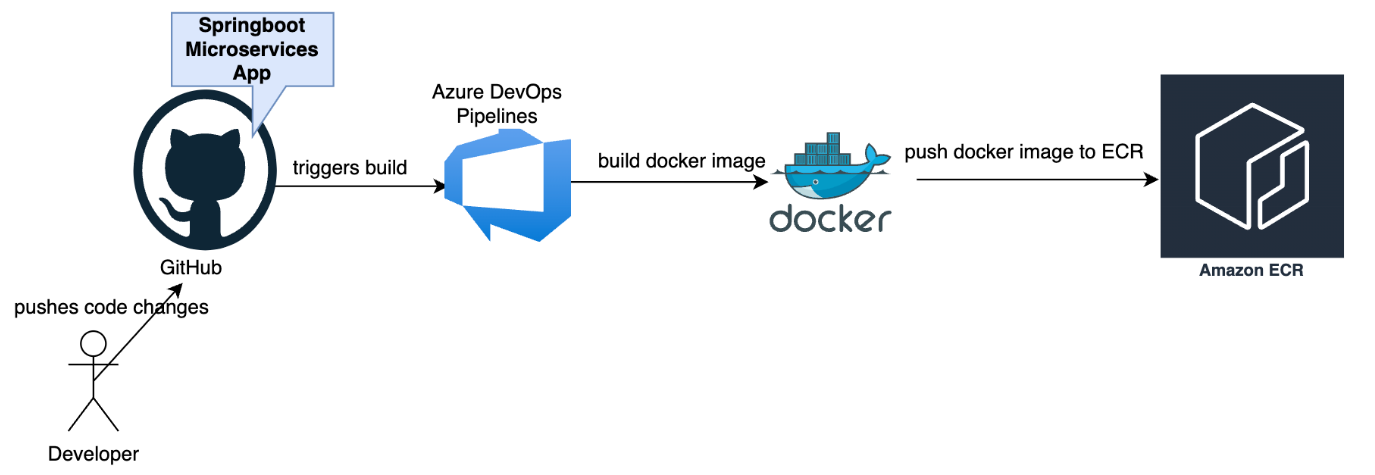
Step 5: Deploy Lambda Function with AWS Integration
If you want to use Lambda Function, you have to create a Docker Image of your ML model and push it to Amazon ECR. Create a Dockerfile with your AWS configuration, including your ML model and its dependencies. Set up a GitHub workflow for building and pushing the Docker image to the Elastic Container Registry (ECR).
Now, let’s deploy an AWS Lambda function that utilizes the Docker image containing your ML model. The process involves creating an IAM role for the Lambda function and implementing a GitHub workflow to streamline deployment.
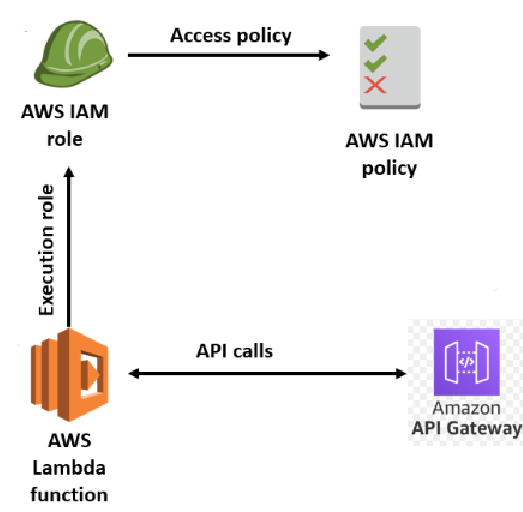
1. Lambda Role Creation:
This step is crucial to grant the Lambda function the necessary permissions to interact with other AWS services such as S3 and ECR. You can follow these steps to create the permission role:
1. Navigate to the AWS Management Console.
2. Open the IAM service and select "Roles" from the left navigation pane.
3. Click "Create role," choose "Lambda" as the service to use this role and proceed.
4. Attach policies granting access to required services, like AmazonS3FullAccess, AmazonEC2ContainerRegistryPowerUser, and AWSLambdaBasicExecutionRole.
5. Complete the role creation process.
You can automate the deployment of the Lambda function using the Docker images stored in Amazon ECR. Implement a GitHub workflow and configure AWS credentials with the Lambda function settings.
Step 6: Deploy Endpoint via API Gateway
This step will set up an API Gateway to create an HTTP endpoint that triggers the Lambda function. The process involves configuring the API Gateway through a GitHub workflow. So, we will define the resources and integration points for the Lambda function to be triggered by the API Gateway.
1. API Gateway Setup:
Let’s create a scalable and accessible HTTP endpoint that can easily integrate with your Lambda function. You can implement a GitHub Actions workflow to define the API Gateway setup steps like below:
Thus, you can create an API Gateway named "MLModelAPI" and use it to handle incoming HTTP requests and trigger the Lambda function.
2. Define Resources and Integration Points:
Now, it’s time to specify the API's structure and define the Lambda function's endpoints. You can manually configure the API Gateway through the AWS Management Console or use AWS CLI commands within your GitHub Actions workflow like the one below.
Thus, the API Gateway gets configured with specific resources and integration points based on the structure needed for your ML model's API.
Step 7: Test Endpoint on Postman
In this final step, we will use Postman to test the deployed endpoint created through the API Gateway.
You can do the testing in Postman by following the below steps:
1. Open Postman and copy the API Gateway URL as the entry point for your ML model that you previously configured through the API Gateway.
2. Set up a new request in Postman and paste the copied URL into the request field.
3. Prepare a set of input data your ML model expects in JSON or other relevant data structures.
4. Execute the request in Postman by sending the sample input to the API Gateway endpoint.
5. Verify the output by examining the response from the API and ensure that it aligns with the expected output based on the input provided.
This step helps confirm that the entire deployment of your ML model in AWS is successful.
Final Thoughts:
Congratulations! You have successfully deployed a Python-based ML model with Hadoop integration on an AWS environment. Hopefully, this technical guide covers the entire process for you to follow! Feel free to adapt the steps based on your specific use case and requirements.
Now, deploy confidently and explore the possibilities of integrating ML models with Hadoop on AWS!


